PIDM accurately retains the appearance of the source style image while
also producing images that are natural and sharper.
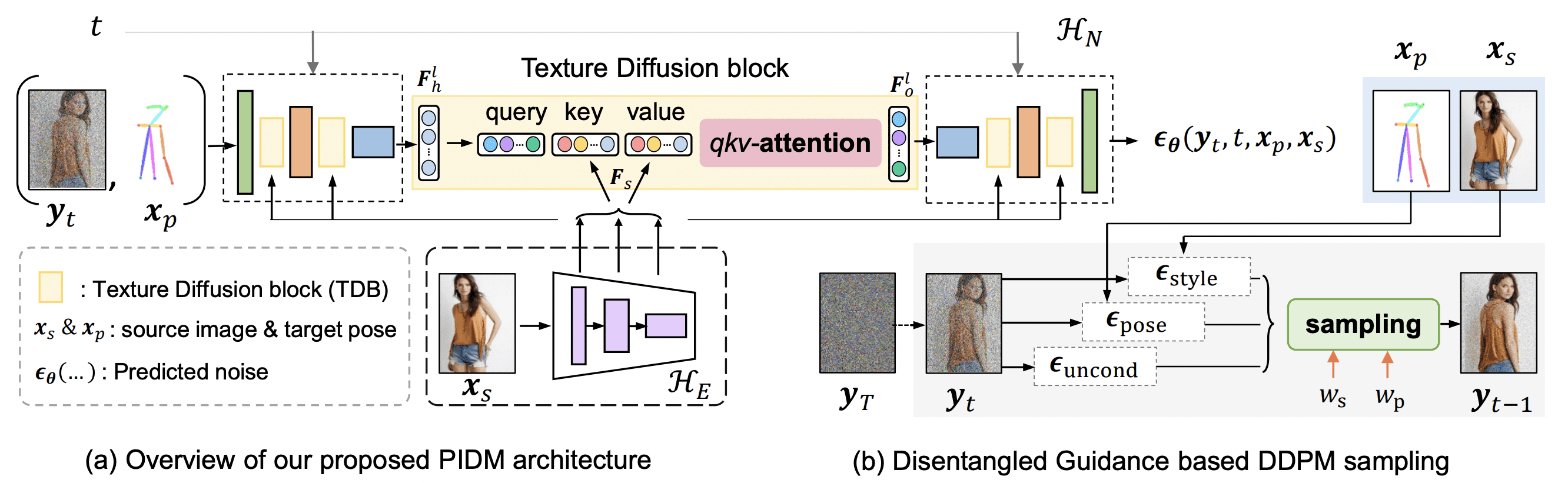
Overview
In this
work, we show how denoising diffusion models can be applied for high-fidelity person image synthesis with strong
sample diversity and enhanced mode coverage of the learnt
data distribution. Our proposed Person Image Diffusion
Model (PIDM) disintegrates the complex transfer problem
into a series of simpler forward-backward denoising steps.
This helps in learning plausible source-to-target transformation trajectories that result in faithful textures and undistorted appearance details. We introduce a ‘texture diffusion
module’ based on cross-attention to accurately model the
correspondences between appearance and pose information available in source and target images. Further, we propose ‘disentangled classifier-free guidance’ to ensure close
resemblance between the conditional inputs and the synthesized output in terms of both pose and appearance information.
A. Qualitative Results of Pose Control
Qualitative Results of Pose Control: Results of synthesizing person images at multiple poses using our proposed PIDM. The left column contains the source images.
B. Qualitative Results of Appearance Control
The results demonstrate the seamless editing capabilities of our model. Images are generated by controlling the appearance of the reference image while maintaining the person’s pose and identity. For each example, the first row contains the style images and the second row contains the generated images
.
C. Qualitative Results in-the-wild scenarios
Our model generalizes well to in-the-wild cases. The source style image (left-most, only ONE) in the above example is taken from an online e-commerce fashion site. PIDM successfully generates multiple pose representation of the given source image.st row contains the style images and the second row contains the generated images.